
Вяртаючыся да сутнасці, прарыў AIGC у сінгулярнасці - гэта спалучэнне трох фактараў:
1. GPT - копія нейронаў чалавека
GPT AI у выглядзе NLP - гэта алгарытм кампутарнай нейронавай сеткі, сутнасць якога заключаецца ў мадэляванні нейронавых сетак у кары галаўнога мозгу чалавека.
Апрацоўка і разумнае ўяўленне мовы, музыкі, малюнкаў і нават смакавай інфармацыі - усё гэта функцыі, назапашаныя чалавекам
мозг як «бялковы кампутар» падчас працяглай эвалюцыі.
Такім чынам, GPT, натуральна, з'яўляецца найбольш прыдатнай імітацыяй для апрацоўкі падобнай інфармацыі, гэта значыць неструктураванай мовы, музыкі і малюнкаў.
Механізм яго апрацоўкі - гэта не разуменне сэнсу, а хутчэй працэс удакладнення, ідэнтыфікацыі і асацыявання.Гэта вельмі
парадаксальная рэч.
Раннія алгарытмы семантычнага распазнання маўлення па сутнасці стварылі мадэль граматыкі і базу дадзеных маўлення, а затым супаставілі маўленне са слоўнікавым запасам,
затым змясціў слоўнік у граматычную базу дадзеных, каб зразумець значэнне слоўніка, і, нарэшце, атрымаў вынікі распазнавання.
Эфектыўнасць распазнавання гэтага распазнавання сінтаксісу, заснаванага на «лагічным механізме», вагаецца каля 70%, напрыклад, распазнавання ViaVoice
алгарытм, уведзены IBM у 1990-я гады.
AIGC - гэта не такая гульня.Яе сутнасць заключаецца не ў тым, каб клапаціцца аб граматыцы, а ў стварэнні алгарытму нейроннай сеткі, які дазваляе
кампутар для падліку імавернасных сувязяў паміж рознымі словамі, якія з'яўляюцца нейронавымі, а не семантычнымі сувязямі.
Падобна да вывучэння роднай мовы ў дзяцінстве, мы вывучалі яе натуральна, а не вывучалі «дзейнік, выказнік, дапаўненне, дзеяслоў, дапаўненне»,
а затым разуменне абзаца.
Гэта мадэль мыслення ІІ, якая заключаецца ў распазнаванні, а не ў разуменні.
Гэта таксама падрыўное значэнне штучнага інтэлекту для ўсіх класічных мадэляў механізмаў - камп'ютэрам не трэба разумець гэтае пытанне на лагічным узроўні,
а лепш вызначыць і распазнаць карэляцыю паміж унутранай інфармацыяй, а потым ведаць яе.
Напрыклад, стан патоку электраэнергіі і прагназаванне электрасетак заснаваны на класічным мадэляванні электрасеткі, дзе матэматычная мадэль
механізм усталёўваецца, а затым збліжаецца з дапамогай матрычнага алгарытму.У будучыні гэта можа не спатрэбіцца.ШІ непасрэдна вызначыць і прагназуе a
пэўны мадальны шаблон, заснаваны на статусе кожнага вузла.
Чым больш вузлоў, тым менш папулярны класічны матрычны алгарытм, таму што складанасць алгарытму ўзрастае з павелічэннем колькасці
вузлоў і геаметрычнай прагрэсіі ўзрастае.Тым не менш, ШІ аддае перавагу мець вельмі буйнамаштабны паралелізм вузлоў, таму што ШІ добра ідэнтыфікуе і
прагназаванне найбольш верагодных рэжымаў сеткі.
Няхай гэта будзе наступны прагноз Go (AlphaGO можа прадказаць наступныя дзясяткі крокаў з незлічонымі магчымасцямі для кожнага кроку) або мадальны прагноз
складаных метэаралагічных сістэм дакладнасць штучнага інтэлекту значна вышэйшая, чым у механічных мадэляў.
Прычына, па якой электрасетка ў цяперашні час не патрабуе штучнага інтэлекту, заключаецца ў тым, што колькасць вузлоў у сетках 220 кВ і вышэй, якія кіруюцца правінцыйнымі
дыспетчарства невялікае, і мноства ўмоў усталявана для лінеарызацыі і разрэджвання матрыцы, што значна зніжае вылічальную складанасць
мадэль механізму.
Тым не менш, на этапе патоку электраэнергіі размеркавальнай сеткі, сутыкаючыся з дзесяткамі тысяч ці сотнямі тысяч вузлоў харчавання, вузлоў нагрузкі і традыцыйных
матрычныя алгарытмы ў буйной размеркавальнай сетцы бяссільныя.
Я лічу, што распазнаванне вобразаў штучнага інтэлекту на ўзроўні размеркавальнай сеткі стане магчымым у будучыні.
2. Назапашванне, навучанне і генерацыя неструктураванай інфармацыі
Другая прычына, па якой AIGC зрабіў прарыў, - гэта назапашванне інфармацыі.Ад аналагава-цыфравага пераўтварэння маўлення (мікрафон + PCM
выбарка) у аналагава-цыфравае пераўтварэнне малюнкаў (CMOS+карціраванне каляровай прасторы), людзі назапасілі галаграфічныя дадзеныя ў глядзельнай і слыхавой
палі вельмі таннымі спосабамі за апошнія некалькі дзесяцігоддзяў.
У прыватнасці, шырокамаштабная папулярызацыя фотаапаратаў і смартфонаў, назапашванне неструктураваных дадзеных у аўдыёвізуальным полі для чалавека
пры амаль нулявых выдатках і выбуховае назапашванне тэкставай інфармацыі ў Інтэрнеце з'яўляюцца ключом да навучання AIGC - наборы навучальных даных недарагія.
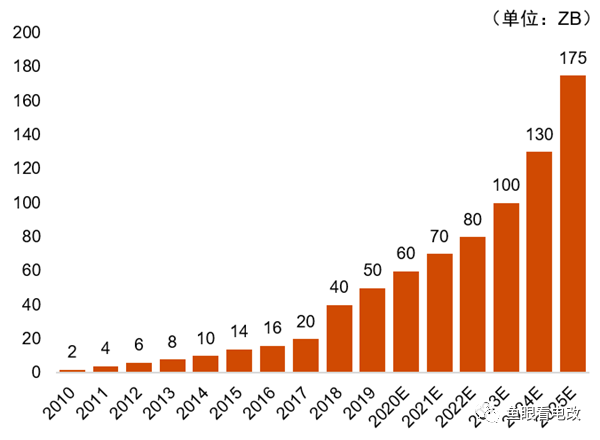
На малюнку вышэй паказана тэндэнцыя росту глабальных даных, якая выразна паказвае экспанентную тэндэнцыю.
Гэты нелінейны рост назапашвання даных з'яўляецца асновай для нелінейнага росту магчымасцяў AIGC.
АЛЕ большасць гэтых даных - гэта неструктураваныя аўдыявізуальныя даныя, якія назапашваюцца без выдаткаў.
У сферы электраэнергіі гэтага не дасягнуць.Па-першае, большая частка электраэнергетычнай галіны - гэта структураваныя і паўструктураваныя даныя, напрыклад
напружанне і ток, якія з'яўляюцца кропкавымі наборамі даных часовых шэрагаў і паўструктураванымі.
Наборы структурных даных павінны быць зразумелыя камп'ютэрам і патрабуюць "выраўноўвання", напрыклад, выраўноўвання прылад - даныя напружання, току і магутнасці
камутатара неабходна выраўнаваць з гэтым вузлом.
Больш клопатам з'яўляецца выраўноўванне па часе, якое патрабуе выраўноўвання напружання, току, актыўнай і рэактыўнай магутнасці на аснове шкалы часу, так што
наступная ідэнтыфікацыя можа быць выканана.Ёсць таксама прамыя і зваротныя напрамкі, якія ўяўляюць сабой прасторавае выраўноўванне ў чатырох квадрантах.
У адрозненне ад тэкставых дадзеных, якія не патрабуюць выраўноўвання, абзац проста закідваецца на кампутар, які вызначае магчымыя інфармацыйныя асацыяцыі
самастойна.
Для ўзгаднення гэтага пытання, напрыклад, выраўноўвання абсталявання для бізнес-даных, неабходна пастаяннае выраўноўванне, таму што асяроддзе і
размеркавальная сетка нізкага напружання кожны дзень дадае, выдаляе і мадыфікуе абсталяванне і лініі, а сеткавыя кампаніі марнуюць велізарныя працоўныя выдаткі.
Як і «анатацыя даных», кампутары не могуць гэтага зрабіць.
Па-другое, кошт збору даных у энергетычным сектары высокі, і замест мабільнага тэлефона патрэбны датчыкі, каб размаўляць і фатаграфаваць.»
Кожны раз, калі напружанне зніжаецца на адзін узровень (або суадносіны размеркавання магутнасці памяншаюцца на адзін узровень), неабходныя інвестыцыі ў датчык павялічваюцца
як мінімум на адзін парадак велічыні.Каб дасягнуць зандзіравання на баку нагрузкі (на канцы капіляра), гэта нават больш маштабныя лічбавыя інвестыцыі».
Пры неабходнасці ідэнтыфікацыі пераходнага рэжыму электрасеткі патрабуецца высокадакладная высокачашчынная дыскрэтізацыя, а кошт яшчэ вышэй.
З-за надзвычай высокіх гранічных выдаткаў на збор і выраўноўванне дадзеных электрасетка ў цяперашні час не можа назапашваць дастатковую колькасць нелінейных
рост інфармацыі аб даных для навучання алгарытму для дасягнення сінгулярнасці штучнага інтэлекту.
Не кажучы ўжо пра адкрытасць даных, для магутнага стартапа AI немагчыма атрымаць гэтыя даныя.
Такім чынам, перад штучным інтэлектам неабходна вырашыць праблему набораў даных, інакш агульны код штучнага інтэлекту нельга навучыць ствараць добры штучны інтэлект.
3. Прарыў у вылічальнай магутнасці
У дадатак да алгарытмаў і дадзеных, прарыў сінгулярнасці AIGC таксама з'яўляецца прарывам у вылічальнай магутнасці.Традыцыйныя працэсары - не
падыходзіць для буйнамаштабных адначасовых вылічэнняў нейронаў.Менавіта прымяненне графічных працэсараў у 3D-гульнях і фільмах робіць буйнамаштабныя паралельныя
магчымыя вылічэнні з плаваючай кропкай + струменевыя вылічэнні.Закон Мура дадаткова зніжае вылічальныя выдаткі на адзінку вылічальнай магутнасці.
ШІ электрасеткі, непазбежная тэндэнцыя ў будучыні
З інтэграцыяй вялікай колькасці размеркаваных фотаэлектрычных і размеркаваных сістэм захоўвання энергіі, а таксама з патрабаваннямі прымянення
віртуальныя электрастанцыі з боку нагрузкі, аб'ектыўна неабходна праводзіць прагназаванне крыніцы і нагрузкі для сістэм размеркавальнай сеткі агульнага карыстання і карыстальнікаў
размеркавальныя (мікра) сеткавыя сістэмы, а таксама аптымізацыя патоку электраэнергіі ў рэжыме рэальнага часу для размеркавальных (мікра) сеткавых сістэм.
Вылічальная складанасць на баку размеркавальнай сеткі на самай справе вышэй, чым складанасць планавання сеткі перадачы.Нават для рэкламнага роліка
складанасць, могуць існаваць дзясяткі тысяч нагрузачных прылад і сотні камутатараў, і попыт на працу мікрасеткі/размеркавальнай сеткі на аснове штучнага інтэлекту
кантроль паўстане.
З нізкім коштам датчыкаў і шырокім выкарыстаннем сілавых электронных прылад, такіх як цвёрдацельныя трансфарматары, цвёрдацельныя выключальнікі і інвертары (пераўтваральнікі),
інтэграцыя зандзіравання, вылічэнняў і кіравання на мяжы электрасеткі таксама стала наватарскай тэндэнцыяй.
Таму за АІГК электрасеткі - будучыня.Аднак сёння неабходна не адразу выкарыстоўваць алгарытм штучнага інтэлекту, каб зарабляць грошы,
Замест гэтага спачатку вырашыце праблемы пабудовы інфраструктуры даных, неабходныя ІІ
Ва ўмовах уздыму AIGC неабходна дастаткова спакойна думаць пра ўзровень прымянення і будучыню энергетычнага штучнага інтэлекту.
У цяперашні час значнасць сілавога штучнага інтэлекту невялікая: напрыклад, на спотавым рынку размешчаны фотаэлектрычны алгарытм з дакладнасцю прагназавання 90%.
з парогам гандлёвых адхіленняў у 5%, і адхіленне алгарытму знішчыць увесь гандлёвы прыбытак.
Дадзеныя - вада, а вылічальная магутнасць алгарытму - канал.Як здарыцца, так і будзе.
Час публікацыі: 27 сакавіка 2023 г